
A Morphological Performance Theory
Robert Beard (1987)
This section describes the performance theory of Lexeme-Morpheme Base Morphology, a complete theory of linguistic morphology. I say "complete" because it not only provides a competence theory of inflectional and derivational morphology and the relation between them, but offers a theory of morphological performance theory as well. The performance theory is called "Lexical Stock Expansion" for reasons this section makes clear. In Gussmann, Edmund (ed.) Rules and the Lexicon: Studies in Word-Formation. Lublin: Catholic University Press, 1987, pp. 23-42.
1. The Problem
So many different types of formal and semantic anomaly have been catalogued in the recent literature that some linguists have abandoned hope of describing lexical processes in terms of regularity. This is unfortunate, since the preponderance of empirical and theoretical evidence still weighs in favor of a lexical component within the grammar, i.e. a strictly regular one. Although much has been written about 'lexical irregularity', there still has been no focused attempt to isolate and define the various types of lexical problems subsumed under this rubric. The purpose of this paper is to address this problem in hopes of increasing our perception of lexical regularity by decreasing the number of ostensible irregularities.
If lexical derivation is not the concatenative process implied by the traditional term 'word formation', but a deep, abstract, semantic process separate from affixation (Beard 1981, Laskowski 1981, Szymanek 1985a), then what is the explanation of 'lexical irregularity'. Semantic exceptions are more critical to lexical theory than formal irregularities if they represent anomalies of true lexical (i.e. not morphological) rules. An explanation of the semantic irregularites of lexical (L-) derivation will greatly reduce the barriers preventing a complete theory of L-derivation and reveal more of the regularity of lexical grammar.
This section will begin and conclude with an examination of a particularly vexing type of semantic irregularity, 'derivate polysemy'. Between beginning and conclusion it will isolate and define several formal and semantic problems which comprise a class of extragrammatical, performative rules. The final result will hopefully be a finer and more discriminating set of terms and concepts with which to analyze lexical processes.
1.1 'Word-Base' Morphology
Recent linguists have attacked the question of semantic irregularity from two directions. Aronoff (1976), Dowty (1979) and Matthews (1974) have returned to 'word-based' morphology, even in the absence of any definition of the term 'word'1. A major advantage of a 'word-based' theory is that it predicts the storage of derived lexemes ('words') subsequent to derivation. In storage, 'words' may undergo various extragrammatical processes which alter their meanings with time in both random and principled ways. This process is generally referred to as 'semantic drift', ostensibly taken from Sapir's term 'linguistic drift' (Sapir 1921).
But the term 'semantic drift' is misleading. Certainly the meaning 'mechanism for changing gears' did not slowly bifurcate from the meaning 'any process of transmitting' associated with the phonological cluster, /trænzmišan/. Nor does evidence indicate any gradual migration of the secondary meaning from another phonological cluster with the same meaning in the sense of 'Wortfeldtheorie' (Trier 1931). Rather, a real, individual speaker, faced at a specific point in time and space with the task of designating some phonological cluster which would refer to automotive transmissions, intentionally selected transmission for that referential function.
| (1) |
transmission (automotive) |
suspension (automotive) |
| |
radiator (automotive) |
percolator (appliance) |
| |
recession (economic) |
depression (economic) |
| |
reservation (Indian) |
depression (economic) |
| |
elevator (lift) |
escalator (stairs) |
| |
destroyer (naval |
submarine (naval) |
| |
woodpecker (bird) |
redcap (porter) |
'Linguistic drift' simply does not explain examples such as (1). Any period during which all people who wore red hats were widely called 'red caps' or all underwater objects, 'submarines', was extremely short if such existed at all. But the point is that no period was necessary for none elapsed in the other instances. The terms escalator, elevator, percolator were originally trade terms, referring to new inventions. The adoption of these lexical derivates was in each case instantaneous, made by an inventor or perhaps even by a board of directors. The secondary meanings of these terms could not have slowly evolved from the primary, transparent meanings.
The theoretically relevant factors seem to be that the secondary meanings of (1) were
(2a) added consciously by real, non-ideal individuals,
(2b) more or less instantaneously,
(2c) to a normally derived compound or nominalization of some minimally related verb,
(2d) to name a specific type of referent.
This process cannot be wholly linguistic for it is not arbitrary or abstract.2
For sure a process of 'linguistic drift' as Sapir defines it constitutes the basis of diachronic change, and semantics no doubt is included in this process. However, evidence does not indicate that semantics is more specially involved than phonology or syntax.
| (3) |
|
holiday |
sloth |
| |
|
wealth |
disease |
| |
|
dead |
atonement |
| |
|
weary |
ghastly |
| |
|
ready |
sorry |
(3) might be called evidence of lexical drift, the lexical reflex of Sapir's linguistic drift. But (3) suggests that semantic drift and phonological drift are intimately interwoven, i.e. the 'drift' is truly 'linguistic' and not solely semantic.
Ostensible instances of semantic linguistic drift without concomitant phonological change do emerge in the data.
| (4a) |
hound |
|
(4b) |
lovely |
hateful |
| |
dog |
|
|
shortly |
awful |
| |
meat |
|
|
ignorance |
enjoy |
| |
flesh |
|
|
attractive |
hardly |
When a lexical prime drifts (4a), some other prime must rise to take on its original meaning unless the meaning is lost, e.g. the shift of the meaning of meat to food when one of the meanings of flesh moved to meat. The net result is a reorganization of the status quo à la Trier: the same primes with different meanings
When an L-derivation drifts (4b), it disengages from the productive L-derivation rule which generates it. This makes the generation of another form to fulfill the original function essential, thus replacing wealth we have well-being; disease, uneasiness; ghastly, ghost-like; lovely, lovable. Hateful can no longer be said to be a derivate of hate at this point and is entered into the lexicon where it is subjected to L-derivation as any other prime: hateful-ness, hateful-ly. When the meaning of a lexical derivate drifts, it pulls its form with it (holiday, ghastly), or at least isolates it from its derivational origin (awful, lovely).
The class of irregularities represented in (1) is different and a problem because the idiomatic meaning is attached in each to the output of a productive derivation. If the derivate ceases to be productive as in (4b) or if the polysemy occurs in underived primes like run, work, head, no problem arises. The problem arising from (1) is that the forms must not be listed independently in the lexicon for they are predictable; their secondary meanings, however, are not.
At the very least, the responsibility for showing that these forms 'drift' is incumbent upon those who base their theories on this concept. A positive and predictive definition of 'semantic drift' must be developed for sound theory. The theoretical demands of definition are satisfied by simply noting that some lexemes have meanings which fall outside the operation of all known rules. Not all rules are yet known; any attempt at proving irregularity would be at best premature, given the embryonic state of lexicology.
1.2 Broadly Based Indeterminate Rules
Another approach to lexical irregularity has been recently suggested by Aronoff (1980), Clark & Clark (1979) and Selkirk (1982). Clark & Clark propose L-rules (or conventions) of broad generality, e.g. XV → XN (from Aronoff). Such a rule would allow any noun to become a verb of any meaning, so long as it is spoken in '... (a) the kind of situation (b) that [the speaker] has good reason to believe (c) that on this occasion the listener can readily compute (d) uniquely (e) on the basis of their mutual knowledge (f) in such a way that the parent noun denotes one role in the situation, and the remaining surface arguments of the denominal verb denote other roles in the situation' (Clark & Clark 1979:787).
Clark & Clark's rule certainly would be vague and unconstrained in the extreme. It permits verbs like to Bonnie-and-Clyde, to stiff-upper-lip, to teapot, to bargain counter and to Sunday School. In fact, however, the overwhelming majority of denominal verbs which actually enter the general lexicon of English and remain there reflect relations closely paralleling the primary functions of the IE case system (e.g. AGENT, PATIENT, RESULT, SOURCE, GOAL, MEANS, LOCATION, POSSESSIVE, PUNCTUALITY, DURATION3. The indeterminate rule allows L-derivates any meaning readily calculable in a given situation, but it requires further conventions to predict why all but a small and usually fleeting minority bear these few meanings.
The secondary conventions need not be linguistic if we assume a 'core of generic knowledge' which classifies all objects as PLACEABLES, PLACES, TIME INTERVALS, AGENTS, RECEIVERS, RESULTS, ANTECEDENTS and INSTRUMENTS (Clark & Clark's terms). When a listener receives an innovative verbalization, he interprets it in the context of the categories of this 'generic knowledge'. We are still left with two treatments: one for regular meanings, another for irregular ones. However, here the basic linguistic rule accounts for the irregularities while the secondary, nonlinguistic rule accounts for the linguistic regularities—an odd theoretical twist.
An even more fundamental problem with this approach lies in the fact that productive L-rules regularly change lexical SUBclasses, not classes. L-derivation rules involve changes such as PLACE → AGENT; MASCULINE → FEMININE; INTRANSITIVE → TRANSITIVE, but never N → V. Even the ostensible class-changing rules in fact operate on subclasses: e.g. NInst → VTr; AdjQual → VInstr; NCon → AdjPoss. No L-rule transforms a lexical item of a given class to all the subclasses of another class, e.g. VTr → N, where N may be an agentive, locative, imperfective, perfective, patientive, temporal and mercedive noun (Aronoff 1984). The broad-based rule approach provides weak promise indeed of any empirically interesting results.
2. Some Assumptions
An approach to morphology distinguishing L-derivation from affixation, which I call 'Lexeme-Morpheme Base Morphology', is now available in Beard (1981, 1986, 1995) and Laskowski (1981). My model (8) provides for the separation of L-derivation, defined as an abstract, semantic process, from affixation, defined in phonological terms. The remainder of this paper will assume the fundamental conclusions of Beard (1995), so we might review them before proceeding to the major task.
2.1 The Lexeme and the Lexicon
Beard (1981, 1995) argues for L-derivation rules located in a functional subcomponent of the lexicon separate from the storage subcomponent. The storage subcomponent contains only lexical items (lexemes), more or less as defined in recent neurolinguistic studies as controlled by the posterior linguistic (Wernicke's) area of the left hemisphere of the brain, that is,
(5a) the subcomponent is an open class;
(5b) the subcomponent is an unordered class;
(5c) its items have real world (extragrammatical) referents;
(5d) its items have intensional meanings senses)4.
The lexicon according to this model is a storage component for noun, verb, and adjective stems attached to a functional component containing rules which define L-derivations abstractly, i.e. without any reference to affixation.
2.2 Lexemic Extension Rules
Stored lexemes may be extended by a set of relatively automatic rules, which will be referred to hence as 'lexemic (L-)extensions'. These rules occupy a separate subcomponent of the grammar (Dressler 1977c) and extend the lexical potential of a given lexical prime or base, always changing its lexical subclass. These regular, productive L-derivation rules characterize inflectional languages, and produce the transparent meanings of such forms as those in (6). They are the regular semantic elements of traditional 'word formation' rules minus any concrete reference to affixation. The existence of their output is irrelevant, since they are abstract, grammatical rules which operate on types, generating types, and bear no relation to real L-derivational tokens. They are automatically applicable to lexemes in lexical storage.
| |
|
|
re-transmit, out-transmit, over-transmit |
| (6) |
TRANSMIT: |
|
transmitt-er, transmitt-er-s |
| |
|
|
transmiss-ion, transmiss-ion-al |
| |
|
|
(un)transmit-able, (un)transmit-abil-ity |
These rules provide for the passage of a stem from one lexical subclass to another, e.g. transitive verb to Agentive, Locative or Instrumental noun (bake: baker, bakery)5. The actual affixes of (6) are introduced by a separate, extralexical morphological (M-) component (8).
2.3 The Morpheme and the M-Component
The model assumed here further provides for an M-component which describes all the types of morphological marking, e.g. affixation, revoweling, reduplication. Lexical features, inherent and derived, condition the operation of M-rules. This component must be
(7a) a closed class,
(7b) which is paradigmatic;
(7c) its rules have grammatically dertermined referents,
(7c) and no intensional semantics at all.
This class closely parallels those items recent neurolinguistic research has associated with the anterior linguistic (Broca's) area: affixes, particles, conjunctions, pronouns, auxiliaries, post- and prepositions (see Geschwind 1970, 1979 for good summaries)6.
The rule subcomponent of this M-component inserts the affixes marking derivation in contexts determined by the lexical featurization of the stems ordering them. Some lexical features reaching the M-component are inherent features of the stem, some may be added by L-derivation rules; some are lexical features, some are semantic and others are phonological. The M-component, for reasons explicated in Beard (1981) and Bierwisch (1981: 585-589), is situated behind the movement rule(s), but before the P-component.
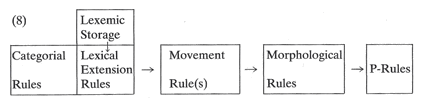
This model allows us to think of L-derivation as an abstract, purely lexical process separate from affix insertion and adjustment rules, which become strictly morphological processes. The semantic irregularity of L-derivation may now be considered apart from any morphological regularity which might accompany it. (Automotive) transmission is morphologically as regular as its semantically transparent homophone, transmission 'any form of transmitting'. The partial irregularity of this example and others such as (4), lies solely in their semantic deviation.7 The goal of this paper, consequently, is to shape a theoretical approach to lexical irregularity which predicts that regularly .derived lexemes may be assigned idiomatic secondary meanings, explains, how this is possible and where the process fits into the improved ESP model of (8).
3. Another Kind of Lexical Rule
This section will adduce evidence for a kind of L-rule qualitatively different from the type of L-extension rule which generates such derivates as (6). This kind of rule may be explained only in terms of the channel along which language is transmitted (Hockett 1960), Hockett & Altman 1968); it violate the design feature 'arbitrariness'. Furthermore, the design feature 'learnability' establishes that language learning and, by implication, use, are unconscious, not intentional. Aspects of language which are consciously and intentionally learned pertain to style or other tangential aspects of language The rules examined in this section are all intentional and conscious; consequently, they must be extragrammatical and constitute another type of L-rule.
3.1. Back Formation: The Presupposition of Priority
Perhaps the most convincing evidence that two types of processes are at work in creating lexical items in IE languages comes from such operations as back formation and loan translation, which presuppose the existence of a theoretically prior set of L-rules. Since laser refers to an instrument, and since er represents the structure of a suffix regularly marking deverbal instrumental derivations, lase has been (mis)perceived as a verb stem and entered as such in the English lexicon as the lexical base of the acronym (cp. Webster's New Collegiate Dictionary and others)8. In terms of the manner in which the verb arrived at its position in the lexicon, we must assume back formation, but in terms of synchronic lexical theory and the grammatical relations characterizing it, laser now becomes the instrumental derivate of lase in just the same sense that shaker is the instrumental derivate of shake, blower, of blow, cutter, of cut.
The instrumental derivation is a single capturable generalization existing in a system of arbitrary L-extensions, e.g. Agentive, Instrumental, Locative, Patientive, participles of various sorts. Back formation, on the other hand, is a process ranging in its application over many if not all these rules.
| (9) |
*Agentive > Transitive Verb |
|
pedlar > peddle |
| |
*Nominalization > Intransitive Verb |
|
emotion > emote |
| |
*Agen. Adjective > Intransitive |
|
lazy > laze |
| |
*Agen. Adjective > Abstract Noun |
|
sassy > sass |
| |
*Plural > Singular |
|
peas > pea |
It extracts spurious lexical primes by analogically operating productive L-rules more or less in reverse. Thus back formation presupposes the prior existence of L-extension rules and thereby proves the existence of two separate sets of L-rules. One set, L-extension, must be prior to the other.
The lexicon does productively generate verbs from instrumental nouns. However, the de-instrumental verbalization differs from back formation in four essentials: (1) it is not predicated on the prior existence of any rules; (2) it operates only on instrumental nouns, (3) its outputs are only transitive verbs and (4) its meaning is regular and consistent across a full, predictable range of bases, roughly, 'employ N in its characteristic way'. Examples include (to) fork, knife, spoon, gun, hoe, plow, harrow, pen, pencil, brush.
Interestingly, this definition fits even those instrumentals accidentally ending on er: (to) hammer, filter, buffer, trigger, cover. So not all lexical primes filling the structural description of the back formation rule undergo it. In fact, many English speakers prefer to laser as a verbalization of the acronym over to lase. But the important point is that the operation of the instrumental L-extension is perfectly regular in that it potentially applies to all instrumental nouns, automatically, to generate grammatical verbs. It does not rely on false perceptions, spurious morphemes, conscious effort, individual performance, nor does it definitionally presuppose the existence of any prior rules.
3.2. Acronymization and Psychological Reality
The introduction of laser into the English language relied but faintly on rules of lexical grammar. The initials of the written forms of the lexemes in the phrase light amplification by stimulated emission of radiation were isolated and a pronunciation was assigned to them on the basis of their linguistically accidental word order, according to the rules associating pronunciation with spelling in English.
Thus the formation of acronyms is also an external process which follows logical and social rules of the linguistic channel. Acronymization is highly dependent upon the customary usage of the writing system and the will of individual, nonideal speakers9. Sometimes free morphemes (prepositions, articles, etc.) are ignored, sometimes not; sometimes only initial letters are copied, sometimes second letters, too, e.g. sonar, from SOund Navigation And Ranging; radar, from RAdio Distancing And Ranging.
Very few speakers generate acronyms and those who do are completely conscious of the process. The original example cited, laser, emerged from a phrase obviously concocted expressly for the purpose of producing an acronym phonotactically compatible with the large majority of instrumental L-extensions in English.
The conscious, intentional, speaker-specific nature of acronymization seems comparable to that of several other means of introducing new, unmotivated lexemes into the lexicon, e.g. borrowing, clipping and loan translation. Although these processes form vague patterns, their patterns cannot be captured in rules as explicit and as ontologically arbitrary as L-extension rules. The fact that they require conscious effort and real context as part of their definition (rather than merely in the description of their performance), precludes their inclusion among purely abstract L-extension rules.
3.3. Clipping: An Indefinable Principledness
Clipping is another example of a derivational process which, although following vaguely definable rules, is also both conscious and unarbitrary. There is a tendency to clip Latinate stems in such a way as to render them more Germanic, but which end of a word will be clipped or, indeed, whether both will be, cannot be predicted. Sometimes the clip follows morpheme boundaries; sometimes it ignores them. Sometimes pronunciation is affected; sometimes, not. Again, we have an indefinable and unarbitrary principledness more akin to performative processes. We do not see the principled behavior of L-extension and affixation rules.
| (10) |
(tele)phone |
|
tele(vision) [British] |
| |
(tele )scope |
|
sub(marine) |
| |
(cara)van |
|
van(guard) |
| |
<(omni)bus |
|
prep(are) |
| |
(ham)burger |
|
rep(resentative) |
| |
(o)possum |
|
perc(olate) |
| |
(rac)coon |
|
bio(logy) |
| |
(e)jac(ulate) |
|
(in)flu(enza) |
The question most closely associated with forms like (10) is 'acceptability', not 'grammaticality', since most have remained slang or substandard. Unlike L-extensions, the meaning of the 'derivate' (output) is identical with that of its underlying form and the parent (input) usually remains the literary norm. The separation of derivation and morphological marking characterizing other L-extension is not in evidence.
Clipping, like acronymization and blending, is not a rule with a fixed structural description for inputs at all and which strictly defines its outputs; rather, it has no structural description for its inputs and only a vaguely defined output. It is not an abstract rule defining grammaticality, but a diachronically and performatively defined convention, a more or less acceptable means of providing, not new extended lexemes, but shorter, more prime-like variants of longer lexemes and phrases. Clipping generates types from individual tokens, not types from types as do L-extension rules
3.4. Lexical Stock Expansion
There is a fourth principal distinction between L-extension and what now may be called 'lexical stock expansion' (LSE) processes. I have taken the name of this class of rules from this distinction, for it is a purely lexical one. While L-extensions specify relations among various paronyms of a given lexical stem, this other kind of rule regularly provides new stems for the storage subcomponent, i.e., expands the stock of lexemes. Thus laser was not a conjugate of any base item already existing in the lexicon at the time it was derived; nor was lase when it was backformed. Rather, in both instances, these forms were new bases created externally and inserted into the storage subcomponent and from which productive L-extensions then become automatically generable:
| (11) |
|
re-laser, out-laser, over-laser |
| |
|
laser-er, laser-er-s |
| Laser |
|
laser-ing, laser-ing-s |
| |
|
(un)laser-able, (un)laser-abil-ity |
With the back formation of lase, precisely the same extensions become au-tomatically available to it.
| (12) |
|
re-laser, out-laser, over-laser |
| |
|
laser-er, laser-er-s |
| Lase |
|
laser-ing, laser-ing-s |
| |
|
(un)laser-able, (un)laser-abil-ity |
The lexicon is thus characterized by two qualitatively different types of rules. L-extensions are wholly arbitrary grammatical rules which operate within the lexicon on whatever stems are available in the storage subcompo-nent. These rules provide access to other lexical subclasses for lexical items of any given subclass. The creativity of such rules is limited to the intensional meanings already in lexical storage and cannot provide open-ended generation of names for the new qualities, objects and activities appearing in the world.
Another class of rules is required to replenish and expand the lexical
stock of primes, one which provides the real 'open-endedness' of the lexicon. This type cannot be controlled by the lexicon since it must have access to sources beyond the lexicon. The description of lexical stock expansion (LSE) rules which has accumulated in this section points directly to their being performative speech act rules of some sort and not grammatical ones.
3.5. A Complete Lexical Model
The evidence surveyed in this section leads to the conclusion that a lexical area of performative memory supplies the lexical storage subcomponent with new base items (lexemes). This in turn suggests a modification of our model (8) to account for all activities which be called in any sense 'lexical'. The model needs a separate, performative component which directly feeds lexical storage.
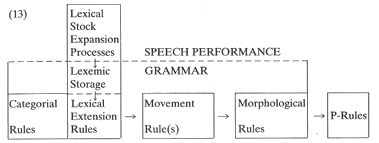
This model allows contact between any given lexicon and the lexicons of other languages, individual speakers or language communities, even with diachrony, via the LSE component10.
Before returning to the questions associated with (1), I would like to momentarily digress to a problem of formal lexical irregularity on which the general distinction of lexical stock expansion and L-extension sheds light.
4.0. Lexical Stock Expansion and Latinate Stems
Aronoff (1976:10-17) proposes a type of morpheme different from that used in his Germanic derivations to explain Latinate stems, i.e. one which is not a sign. This type of morpheme may be empty and nonoccurring alone, but meaningful when conjoined with another morpheme of the same type. All of the sources of such morphemes discussed by Aronoff may be taken as lexical primes; in fact, the question is whether they can be treated as divisible units, since such units would never occur alone.
| (14) |
re?fer |
|
re?mit |
| |
con?fer; |
|
com?mit |
| |
trans?fer |
|
trans?mit |
| |
de?fer |
|
e?mit |
| |
in?fer |
|
. . . |
| |
. . . |
|
sub?mit |
As lexical primes, their various L-extensions are quite predictable:
| (15) |
|
|
re-transfer, out-transfer, over-transfer |
| |
|
|
transfer-er, transfer-er-s |
| |
Transfer: |
|
transfer-al, transfer-al-s |
| |
|
|
(un)transfer-able, (un )transfer-abil-ity |
The problem then arises in explaining our intuition that the primes themselves contain combinations of 'prefixes' re-, de-, sub-, iN-, coN-, trans- plus the somehow deeper 'roots' -fer and -miT, without any accompanying intuition of the meanings they might represent.
In fact, re- is productively used in L-extension, but as an iterative prefix, while de- is a privative prefix in English. Other than in these functions, however, there is no evidence that these morphemes have any value at all to native speakers of English innocent of Latin. such Latinate vocabularve speakers of English innocent of Latin. The creation of such Latinate vocabulary items is, again, an intentional effort undertaken by individual English speakers who have consciously learned Latin or looked up the necessary morphemes in printed Latin dictionaries. The rules by which such lexical items are imported into English presuppose a system of Latin L-extension rules. Transported to English, they enter as new lexical primes or stems, not as extensions of preexistent sterns.
The description of Latinate stern derivation conforms remarkably to the description of LSE processes presented in Section 3. Latinate stems are not derivates of English lexical primes, but are new primes upon which English L-extension rules may freely operate. Latin L-extensions must surely be LSE processes to English.
5.0. Derivate Polysemy and the LSE Component
Let us now return to the question of derivate polysemy as defined in Section 1; that is, to any type of structurally regular L-extension with an irregular or opaque secondary meaning (1). The LSE component now provides us with new alternatives to L-extension rules, linguistic drift and vacuous broadly based rules as explanations of such meanings.
Two aspects of the problem must be addressed. First, we must explain how the secondary meaning is attached to the regular feature could specify a second, idiomatic meaning which the extended, and only the extended, stem may have. This approach has the advantage of characterizing the regular structural identity of transmission1 and transmission2 as theoretical morphological identity (the same M-rule generates both), and the semantic disparity of different meaning—one regular, one idiomatic—as theoretical semantic disparity. One meaning is derived by rule, the other, by lexical featurization. No superfluous theoretical apparatus results, no redundancy arises, and no aspect of the problem is left undefined.
(16) {trænz-mit}
.
.
.
1. "Convey, etc."
2. IFF [ +Noun, +Perfective]: "mechanism for changing gear ratio"
This stem could then be subjected to regular nominalization rules for the perfective nominalization and the semantic interpretation would be properly ambivalent.
This solution is similar to Lakoff's 'hypothetical stem' solution to ostensible derivates whose stems do not occur outside the derivate. Lakoff (1970) proposed such stems for 'derivates' like perdition, e.g. *perdite, etc., which would contain all necessary lexical features for perdition except those which, are added by nominalization. This stem could then be treated like a normal stem and perdition, like the regular nominalization it seems to be.
The disadvantage of this approach is that the meaning 'mechanism for changing gears' is not part of the sense of transmiT and any theory implying this is at odds with the data. Just as Lakoff's solution to the problem of 'stemless derivations' mixes irregular stems with regular ones, this approach mixes irregular semantic features with regular ones
5.1. General Memory and Derivate Polysemy
A third alternative would have transmiT generated by the English lexicon with only its transparent meaning. This is required to preserve the nature of the grammar as a system of linguistic regularities. It also implies that all irregularities must lie somewhere outside the grammar. Taking this point of departure, the next questions are: Where are partial irregularities like the secondary meaning of transmission stored. and how are they related to the formal regularities?
A complete theory of lexical functions must explain how speakers deduce from the sense of a lexeme, what it may refer to in the real world. For example, material attributes like wood(en), steel, plastic are used to refer to objects whose characteristic or sensually dominating part is made of that material referred to by the attribute. A 'plastic' television set might consist predominantly of metals and glass yet still be referred to as 'plastic' because its cover is made of plastic. Adjectives like sad, happy, sick, whose sense clearly restricts them to human referents, may be used in speech to refer to works of art which cause the experiencer to be sad, happy or sick, e.g. a sad story, a happy movie. Rules of lexeme usage like these must be part of general memory, since they involve the use of lexemes in the real world.
The storage of secondary meanings such as that of transmission, may also be stated in terms of general memory, pragmatic knowledge. The secondary meaning becomes the knowledge that the lexical stem transmiT may be submitted to the perfective nominalization in sentences and associated PERFORMATIVELY with the referent class of automotive transmissions. This approach has the appeal of representing all regularity as regularity and all but only irregularity as irregularity. Moreover, it will occasion no new theoretical apparatus since pragmatic knowledge must include knowledge of how to use lexemes in real contexts, i.e. how to predict referents on the basis of sense. It does imply, however, that the secondary meanings of semantic irregularities such as those exemplified in (1) are referents, not senses.
Empirical evidence does indicate that the secondary meaning of the examples of (1) are referent and not sense classes. Lexemes such as those in (1) are seldom if ever subjected to further L-extensions and are seldom if ever used metaphorically in their secondary meaning. Polysemous derivates occasionally may be subjected to L-extensions which are not marked by affixation, e.g. ?I elevatored to the second floor, ?He submarined around the Pacific. But this occurs relatively infrequently and results in derivations of questionable acceptability. Derivates with secondary meanings may transport those meanings into compounds, e.g. elevator operator, but not into derivational compounds, e.g. *multi-elevatored (building), *transmission-al-ity.
This prohibition against further L-extension cannot be due either to the polysemous derivate's being a derivate or the result of the secondary meaning's being idiomatic. Derivates wholly stranded away from their L-extension rule by linguistic drift are not prohibited from further derivation (see 4b): loveli-ness, hateful-ly, awful-ly. The L-extension rules operate on sense alone, for they have no access to referents; they are purely grammatical rules. In order to undergo L-extension, all a lexeme must have is a sense compatible with the functions of L-extension rules. Thus L-extension rules by definition operate only on lexemic sense.
To be used metaphorically, a lexeme must contain a sense decomposable into features. Metaphor is the use of a lexeme to refer to a member of a referent class. which shares only one or two of the features of the lexeme's sense. In saying, 'John is putty (in my hands)', a speaker refers only to the shared feature of 'pliability' and ignores the many unshared ones: animacy, countability, etc. The obvious explanation of the resistance of polysemous derivates to metaphorization is that they 1ack atomizable senses.**
The resistance to further L-extension and metaphorical usage characterizing derivate polysemy suggests that such derivates are not reinserted into lexical storage in the same way, say, as back formations are; instead, it suggests that the secondary meanings of derivates are in fact knowledge of alternate referential uses of regular derivations and not of lexical senses.
This explanation offers a tentative, heuristic definition of reference which distinguishes it from sense. Reference is knowledge of how a lexeme's sense is used in performance to predict referent classes in the real world. It is poss-ible by this definition of reference for a lexeme to have a misbalance in the number of its senses and referents - more or fewer of one or the other. Polysemous derivates are thus derivates with one sense but more than one referent.
The evidence indicates that sense is lexical, bur reference is not. This does not imply that in actual behavior knowledge of reference may not precede that of sense. It may be that most speakers of English learn the referent of transmission2 before they use transmission1. The linguistic priority of trans-mission1 derives from its lexical relation to transmit and does not speak to the question of onto genetic priority. It may well be that knowledge of sense and knowledge of reference are neurologically identical. Lexically, however, they obviously are not.
The advantage of representing derivate polysemy as general knowledge of the use of the perfective nominalization of transmiT, is that it represents derivate polysemy in terms of knowledge of a class of referents, not as sense at all. Since we are assuming that the affixation of transmiT is regular and thus does not require lexical storage, we would misrepresent the formal facts to store the form of transmission: in any way. By separating reference from sense, the third option allows us to explain why most instances of derivate polysemy can not be used metaphorically and predict what must happen for them to become susceptible to metaphorical use.11
The third approach has the disadvantage of considerable vagueness at this stage. This is because 'sense' and its relation to 'reference' are still poorly defined. Little doubt remains that sense and reference are separate components of lexical meanings; but the exact nature of sense continuesto elude final definition. Until clearer definitions of 'sense' and its relation to 'reference' are available, the third alternative presented here must remain, though to a lesser degree, with the first two approaches, under suspicion .
6.0 Conclusions and Remarks
We now have a derivational alternative to lexemic extension which is 'extragrammatical'. In fact, extragrammatical input is precisely what is needed J explain lexical irregularity. The semantic irregularities of (1) are indeed the results of conscious acts of specific, non-ideal speakers. The process involves choosing the form of a regular derivation (see 5), and attaching the new meaning to it. The result is not a new lexeme, but merely a new meaning for a readily generable lexeme.
Although the final synchronic description of derivate polysemy remains to be seen, this paper has hopefully clarified the lexical terminology in useful rays. The separation of performative LSE processes from grammatical L-extension processes reduces the magnitude of the problem of lexical irregularity y assuring us that these issues are not grammatical. The problem of Latinate rimes, linguistic drift and derivate polysemy need no longer intimidate us rom seeking the characteristic rules of the lexicon. Moreover, a clarification of the problem of lexical irregularity should encourage further research into re performative semiregularities which turn regular L-extension outputs into exceptions.
This section also brings us a step closer to charting the character of the lexical storage component. Its open-endedness and lack of obvious grammatical order suggest that it is extragrammatical, dependent upon the real world. But the fact that its classes correspond to the category functions of grammar in inflectional languages suggest that it is somehow a part of grammar (Alinei 1980, Beard 1981). Perhaps it is a bridge between grammar and the real world. Hopefully the terminology introduced here will in some way contribute to a clearer depiction of this component in future.
Notes
1The absence of a definition is the reason the term 'word' will be eschewed here. Beard (1981: 39-45) reviews the well-known problems of defining this term. Nothing is lost by avoiding it: sound lexical theory requires only clear definitions of 'lexeme' and (grammatical) 'morpheme' such as (5) and (7). The lack of a definition of 'word', however, does undermine all attempts at 'word-based' morphology.
2I am assuming grammar to be an ideal or abstract object like Saussure's langue. The most. compelling recent arguments against Chomskyan 'conceptualism' and in favor of abstract grammar may be found in Katz (1981).
3The same functions underlie all IE lexical derivations (Beard 1981, Chapters 8-9) and, apparently, IE nominal compounds (Levi 1978:165, fn. 38).
4It is perhaps the consensus of semanticists today that proper nouns do not have 'sense' or intensional meaning. But the issue remains unclear so long as no solid definition of 'sense' exists. Frege and those who followed him proved conclusively that sense is distinguishable from refer¬ence; however, no one has produced a reliable definition of sense. The position of this paper will be that all lexemes, including proper nouns, have sense, although the latter have a strikingly dif¬ferent kind of sense.
5Beard (1982) demonstrates the existence of a second type of L-rule which merely adjusts the value of such lexical features as gender and number, e.g. [+SINGULAR, -PLURAL] [-SINGU¬LAR, +PLURAL], [+MASCULINE, -FEMININE] [-MASCULINE, +FEMININE]. This paper, then, will present evidence of a third type of L-rule further on.
6This distribution differs from Chomsky's (1981), who would store prepositions with nouns, adjectives and verbs, using the available marking [-VERB, -NOUN]. Chomsky's inclus¬ion of prepositions in a class with nouns and verbs is at odds with the neurolinguistic facts—the only physical empirical evidence of language that we have—but with the linguistic evidence as well. Prepositions must fall into the same category as inflectional affixes, since their function is identical to that of inflection and they are not semantically 'free' forms. Moreover, nouns, verbs, adjectives and adverbs are productively derivable from each other, but prepositions do not par¬ticipate in productive L-extension except as prefixes. See Beard (1984, 1988).
7It might be better to use the term 'lexical' here, for the semantic deviation in partially irregular lexical items is a deviation from the lexical norm of a given L-rule. In the example quoted, the irregularity must be described in terms of a semantic deviation from the perfective nominalization, the transparent function of transmission. The semantics of 'perfective nominali¬zation', like that of 'agent', 'patient', 'animate', 'abstract', 'place' represents lexically relevant semantic concepts and should therefore be distinguished from those semantic concepts which are not relevant to lexical processes. It is more consistent to distinguish between those semantic functions determined by the lexicon, e.g. 'perfective nominalization' and those not.
8In fact, a better interpretation of 'back formation' would cast it in terms of an acceptable form of speech error, since the perceived lexical prime, lase, was originally spurious, a result of mistaking laser for the output of a productive L-extension rule. The fact of acceptability does not speak to the issue of grammaticality (see Bever et al. (1976)); some back formations are treated as er¬rors by the speech community (' ... well-nutrited [nutrition] people', 'Central PA ... a good place to work, live and recreate [recreation]' are two such recently received); others become legitimate lexical primes.
9The phonological or phonetic structure of laser was derived secondarily from rules as-sociating spelling with the sounds of Germanic stems in English. The initial sounds of the words in the phrase with which laser is commonly associated are /l/, /æ/, /s/, /i/ and /r/ , but the phonolog¬ical realization of the word is /lejzər/, not /læsir/. Thus the pronunciation of the lexeme is a deri¬vate of its spelling, an idiomatic one at that, since 's' is not usually pronounced /z/— not the op¬posite, which would be lexically normal.
10 This model raises another issue which will not be settled here. The exclusion of the LSE processes from the grammar is based on their not being arbitrary and regular, as are L-extension and T-rules. But if we examine our definition of lexical storage (5), we cannot ignore that fact that this subcomponent also lacks the qualifications of a grammatical component: it is unordered, it has real world referents which means it must be an open class, and its items have intensional meanings related to their referents, which means they do not have grammatical functions. This description strongly suggests that the lexical storage subcomponent is also extragrammatical; however, since there are undoubtedly lexical (sub)classes suggesting some order, we will not exclude it from the grammar here. This is an important question, however, which must be addressed in future.
11It is interesting to note that these meanings do not thwart the pluralization rule, which is also a derivational rule (Beard 1982). However, pluralization is not an L-extension rule; it in¬volves merely the adjustment of number features which are present in all nominals. Still, further examination of the fact that secondary meanings generally pluralize while resisting all other types of lexical derivation is called for.
References
Alinei, M. 1980. "Lexical Grammar and Sentence Grammar. A Two-Cycle Model". Quaderni di Semantica 1. 33-95.
Aronoff, M. 1976. Word Formation in Generative Grammar. Cambridge, Mass.: The MIT Press.
Aronoff, M. 1978b. "A Reply to Moody". Glossa 13. 115-118.
Aronoff, M. 1980. "Contextuals". Language 56. 744-758.
Beard, R. (1995) Lexeme-Morpheme Base Morphology. SUNY Press: Stony Brook, New York.
Beard, R. (1988) "Neurological Evidence for Lexeme/Morpheme Based Morphology". Theoretical Approaches to Word Formation. Proceedings of the Veszprem Conference, May 1-4, 1986. F. Kiefer (ed.)
Beard, R. 1981. The Inda-European Lexicon: A Full Synchronic Theory. Amsterdam: North-Holland.
Beard, R. 1982. "The Plural as a Lexical Derivation". Glossa 16. 133-148.
Beard, R. 1984. "Prepositions and Case". Zbornik za filologiju i lingvistiku 27-28. 57-63.
Beard, R. 1986. On the Separation of Derivation from Morphology: Toward a Lexeme/Morpheme Based Morphology. Bloomington, Ind.: Indiana University Linguistics Club.
Beard; R. 1976. "A Semantically Based Model of a Generative Lexical Word-Formation Rule for Russian Adjectives". Language 52, 108-120.
Bever, T., J. Katz and T. Langendoen (eds) 1976. An Integrated Theory of Linguistic Ability. New York: Crowell.
Bierwisch, M. 1981. "Linguistics and Language Error". Linguistics 19. 581-626.
Bloomfield, L. 1933. Language. London: Allen Unwin.
Chomsky, N. 1981. Lectures on Government and Binding. Dordrecht: Foris Publications.
Clark, H. and E. Clark 1979. "When Nouns Surface as Verbs". Language 55. 767-810.
Dowty, D. 1979. Word Meaning and Montague Grammar. Dordrecht: Reidel.
Dressler, W. U. 1977a. "Elements of a Polycentristic Theory of Word Formation". Wiener Linguistische Gazette 15. 13-32.
Dressler, W. U. 1977c. Grundfragen der Morphonologie. Wien: Osterreichische Akademie der Wissenschaften.
Hockett, C. F. 1960 "The Origin of Speech". Scientific American, 203, pp. 89–97
Hockett, C. F. and S. Altmann 1968. "A Note on Design Features". In T. A. Sebeok (ed.) Animal Communication. Bloomington: Indiana University Press.
Katz. J. J. 1981. Language and Other Abstract Objects. Totowa, N. J.: Rowman and Littlefield.
Lakoff, G. 1970. Irregularity in Syntax. New York: Holt, Rinehart and Winston.
Laskowski, R. 1974. "The e+o, e+a Alternation in Polish Verbal Morphology and the Slavic Secondary Imperfectives". Makedonskij Jazyk 26. 63-80.
Laskowski, R. 1981. "Derywacja słowotwórcza". In J. Bartminski (ed.), Pojęcie derywacji w lingwistyce Lublin 1981, 107-126.
Lees, R. B. 1960. The Grammar of English Nominalizations. Bloomington: Indiana University Press.
Matthews, P.H. 1974. Morphology: An Introduction to the Theory of Word Structure. Cambridge: Cambridge University Press.
Sapir, E. 1921. Language. New York: Harcourt, Brace.
Szymanek, B. 1985a. English and Polish Adjectives. A Study in Lexicalist Word-Formation. Lublin: Katolicki Uniwersytet Lubelski.
Trier, J. 1931. Der deutsche Wortschatz im Sinnbezirk des Verstandes. Heidelberg: Winter.