A Note on Speech Errors1
Robert Beard (1996)
(Unpublished)
1. The Cognitive Implications of Linguistic Theory
In a rare rebuttal to a review of a text in cognitive science by Stephen Anderson (1990), George Miller (1991) accused linguists of avoiding proof of their theories with psychological data. Anderson had faulted the author of the text under review of ignoring the work of linguistic theoreticians; Miller pointed out that the fault runs both ways. This article in a sense is a response to Miller's accusation for it uses the data of psycholinguistics to distinguish two theories of morphology and demonstrate that one is superior to the other in its production 'transparency', i.e. to predict not only the symbolic output of morphological operations, but the speech act (performance) phenomena of morphology as well. It follows in a the tradition of Victoria Fromkin (1970 and onwards) and a handful of other linguists to do the same.
A good deal of work in speech error theory has been done by psychologists such as Garrett, Sternberger, Shattuck-Hufnagel, Levelt, and Dell. This paper represents a different approach to some of the same points they make: rather than seeking a theory of speech production in the empirical data of speech errors, this one attempts to justify a theory with that data. It is therefore a linguistic approach to speech errors, demonstrating (or, better, reiterating what Fromkin has long argued) that speech errors offer a rich source of evidence for theories of competence. It argues that we must not limit our expectations of a linguistic model to the generation of all WELL-FORMED and the exclusion of ILL-FORMED phrases. A well-constructed model must also distinguish, among ill-formed phrases, those which are POSSIBLE and those which are IMPOSSIBLE, and explain the difference.
For more than a decade now psycholinguists have noticed a difference between major- (open-) and minor (closed-) class morphemes in normal and pathological speech errors. Garrett (1984: 184), for example, concludes that "vocabulary contrast [is] supported by the differential sensitivity of major-class words (N, V, Adj) and minor-class words (Conj, Quant, Comp, Rel, Demo, etc.) to sound-exchange processes: the former contribute to sound exchange, the latter do not. Exchange and shift errors also distinguish the two classes, for the former are dominantly movements of open class elements while the latter are dominantly movements of closed class elements, and this applies with equal force to bound and free forms. Dell (1986) and Stemberger (1991) note the same distinction. Some offer guarded explanations; others note the difference and pass on to other things. No satisfactory explanation of this phenomenon has thus far been offered; however, there is a current school of morphological theory which predicts this distinction in ways that others do not. We assume that this fact poses no little interest to both psychological and linguistic theoreticians.
1.1 Testing theories of competence
At the same time, two schools of morphological research have emerged; Aronoff (1994) refers to them as MORPHEME-BASED MORPHOLOGY and LEXEME-BASED MORPHOLOGY. The difference between the two are roughly this: morpheme-base morphology assumes that the MORPHEME is a sign (the minimal meaningful element of language) and makes no fundamental distinction between LEXEMES and GRAMMATICAL MORPHEMES. The assumption is that stems and affixes, for example, are roughly theoretically equivalent identical (Lieber 1992, Sadock 1991). Lexeme-based morphology, on the other hand, assumes with the classic grammarians, that only the word is a sign. Sublexical units like stems and affixes may or may not be signs. In fact, lexeme-based morphologists distinguish between stems (lexemes) and morphological realizations (grammatical morphemes). Lexemes are signs; morphological realizations either may not be or must not be.
The question is, as usual, how do we determine which theory offers the greater likelihood of success? Matthews (1972), Anderson (1992), Aronoff (1993) and Beard (1995) have laid out in brutal detail the theoretical case for lexeme-based theories, but the assumption of the morphemic sign continues to dominate linguistic studies (Chomsky 1993, 1995; Lieber 1992, Di Sciullo & Williams 1987, Halle & Marantz 1993, Sadock 1991, Scalise 1984, Selkirk 1982). This paper will use the psycholinguistic data of speech errors for the first time to demonstrate that the linguistic superiority of lexeme-based theories extends to the arena of language production. Specifically, it will argue that a theory of morphological production may be transparently derived from a carefully architectured lexeme-based theory of morphology while the same is not true of morpheme-based theories.
If the ultimate purpose of linguistic theory is to predict speech, the exclusion of ill-formed words and constructions provides only a low-level test. The differences between possible and impossible derivations (among 'ill-formed' outputs) provide a more sensitive diagnostic of how the components of competence interact during speech.2 We will distinguish, among ill-formed words and phrases, those which are ill-formed but grammatically possible (*) from those which are ill-formed but impossible (&) Although some impossible forms may be the result of nonlinguistic production operations, to the extent production operations map competence (linguistic knowledge) to speech, the types of errors found in speech production should be limited to and shaped by the content over which they operate. In other words, theories of competence which lend themselves to a reasonable theory of speech production are more attractive than those which do.
1.2 Type Transparency Hypothesis
We will assume that competence theories which predict speech production with the greatest degree of 'transparency' in the sense of Berwick and Weinberg (1984) are the better theories. If one theory is preferable to two in predicting a given array of data, then one theory with a minimal secondary theory is better than one theory with less than a minimal secondary theory. In terms of linguistic theory, it follows that the competence theory which most transparently projects a production theory is preferable to one less directly projected from competence. This is an argument from Occam's Razor.
1.3 Outline of this Paper
Section 2 will summarize the essential properties of lexeme-based and morpheme-based morphological theories which will be the focus of this paper. Section 3 will then examine the predictions of these two theories if they are taken as type transparent for production models: Section 4 will then examine the speech error data which distinguishes lexemes from grammatical morphemes to see whether the distinction transparently reflects distinction in lexeme-based models. Section 5 examines an alternative account of the data available to morpheme-based models for viability. Section 6 will present a summary and our conclusions.
2. A Theoretical Polarity Among Current Morphological Models
A decade ago, only three linguists in the US were even working in theoretical morphology. Things have changed radically: today there are so many morphological theories that it is full-time job just keeping abreast of them: Anderson's 'A-Morphous' morphology, Halle & Marantz's 'Distributed morphology', Matthews 'Word-and-Paradigm' morphology, Sadock's 'Autolexical syntax', Lieber's 'Word syntax', and now Chomsky's 'Checking theory', among others. They all form two groups, however, in their assumptions about one issue: the number and nature of morphological primitives. Chomsky, Halle, Marantz, Lieber, Sadock, and the majority of other morphologists still operate under the assumption3 that lexemes and grammatical morphemes are signs, similar enough to be stored together and copied by the same insertion rule. The lexeme-based theories of Anderson, Aronoff, Beard, and Matthews, however, argue that only the word is a sign because words must contain lexemes, which are N, V, and A stems, and lexemes by definition are signs. Grammatical morphemes, on the other hand, may or cannot be signs, depending on the particular theory and behave in radically different ways than lexemes. This section will examine these two positions on this issue alone.
2.1 Morpheme-Based Morphology
The crucial aspect of morpheme-based theories of morphology for this paper is that they assume a single morpheme, it a sign, i.e. a mutually implied pairing of sound and meaning. Within this school of thought, lexemes and grammatical morphemes, bound and free, are the same. Language comprises sounds which symbolize meanings and morphology encodes those sounds to be meaningful, whether the meanings are grammatical or semantic categories or both. Lexical and grammatical morphemes do not differ significantly enough to be assigned autonomous components or defined distinctively in theories of competence. Let us now examine these two fundamental assumptions of morpheme-based theories.
2.1.1 Stems and affixes are signs ('morphemes')
Within morpheme-base theories, both stems and affixes are mutually implied triplets of semantic, grammatical, and phonological representations.4 Lieber (1992: 22), for example, asserts that 'affixes like -ize will be regarded as bound verbs, with all of the properties to be expected of verbs (e.g. having an argument structure, possessing the morphosyntactic features of verbs)'. Sadock (1991: 37) goes to far as to call affixes 'lexemes', e.g. 'Let us assume the lexical entry in L13 for the English verbal inflection -s. Then we can see that the three lexemes, Fido, bark, and -s can lexicalize all three trees ....' Sadock goes on to illustrate the suffix -s with the following figure, Sadock's (L13), p. 37:
| (1) |
-s |
| |
Syntax = nil |
| |
Semantics = O-1 |
| |
Morphology = [V[-1] V[-0] ___] |
Compare this illustration with the lexical entry for Fido, Sadock's (L2), P: 31:
| (2) |
Fido |
| |
Syntax = N[2] |
| |
Semantics [Q [Q[-1] DEF] [F[ F[-1] __] X ]] |
| |
Morphology = N[-1] |
The details of these representations are not germane to the point of this article; important is the fact that a fundamental attribute of morpheme-base morphology is the assumption that there is a single morpheme, the minimal meaningful unit of language, and that all stems, affixes, and other types of morphological modification (e.g. reduplication, revoweling, stem mutation) are may be described under this one rubric.
All these objects are signs, mutually implied associations of sound and meaning or triplets of phonological, grammatical, and semantic representations.5 This conclusion is forced by the assumption that all morphemes are the same and the empirical fact that all lexical morphemes have intensional and extensional meaning. Affixes and other forms of morphological marking generally seem to be meaningful, too; thus -s seems to mean 'Plural', or 'Possessive', or '3rdSg' in its various uses. Stem reduplication and revoweling seems to indicate the same sort of categories. If we use the term 'meaning' in its broadest sense, specifically, to include grammatical as well as intensional meaning, and allow grammatical and semantic representations, we derive the sound-meaning consistency that we need to maintain that all morphemes are alike. The linguistic sign is the simplest possible representation of the relation between linguistic sound and meaning and hence adds an elegance to the theory of morphemes and contributes to our understanding of language learnability. Other, more complicated though logically possible relations between sound and meaning are ruled out theoretically.
2.1.2 Morphemes are stored in a single lexicon
Since they are essentially identical, all morphemes are stored in a single lexicon (Bloomfield 1933: 161-163). Since stems and affixes are essentially identical, they may be inserted into syntactic structure by the same lexical copying mechanism, usually positioned before movement rules in current linguistic models.6 The storage of all meaningful linguistic elements in a single component offers a theoretical elegance for it implies a single origin for meaning from a single type of linguistic object, the morpheme. Moreover, these objects are copied into phrase structure by a single mechanism, essentially, "COPY OVER (x,y)", where y is a complex symbol in a minimal projection of a phrase, x is a lexical item, and x is not incompatible with y. In other words, if a minimal projection contains the categories of N, an N but not an A or V may be copied over it from the lexicon. This same operation applies to stems, affixes, and since McCarthy (1981) and Marantz (1982), Semitic revoweling and reduplication.
An elegant entailment of the single-morpheme-single-lexicon model is that lexical derivation, such as the derivation of baker from bake, is a simple matter of compounding the verb bake and the noun -er. The rule required differs in no significant respect from that deriving drawbridge from the verb draw and the noun bridge. In either case, lexemes bearing phonological, grammatical, and semantic representations are combined in such a way that the one to the right determines the category of the output. The phonology of the output is the sum of the phono-logical representations of the input plus allophony, the sum of the grammatical representations and the sum of the semantic representations. The simplicity and elegance of the morpheme base model should not be abandoned lightly.
In summary, then, what we are calling 'morpheme-based' theories of morphology subscribe to the following two assumptions, one of which may entail a third: (a) there is but one morphological primitive, the morpheme, it a linguistic sign and (b) all these objects are stored and copied from a single lexicon. Because these theories do not distinguish closed and open class (or major and minor) lexical items, they force the explanation of this distinction on the theory of production. There is a class of theories, however, which make this distinction at the level of competence. This means that production theories can ignore the distinction for it is a part of the speaker's linguistic, not processing, knowledge. It is to this class of theories that we turn now.
2.2 Lexeme-Base Morphology
Aronoff (1993) argues for a type of morphological theory which he calls 'lexeme-based' theories, designed primarily by himself, Peter Matthews, Stephen Anderson, and Robert Beard. These theories separate lexical morphemes (lexemes) from (grammatical) morphemes to varying degrees. Matthews and Anderson include derivational morphemes in their lexicon and treat only inflectional morphemes distinctly; Beard makes an absolute distinction between all open class items (lexemes) and all closed-class items (morphemes), predicting no universal morphological difference between free or bound grammatical morpheme, but the most fundamental difference between N, V, and A stems and everything else in language. Let us first examine the linguistic underpinnings of lexeme-based theories; then we will turn to psychological justifications.
2.2.1 Only lexemes (N, V, A stems) are signs stored in a lexicon
Under lexeme-based morphologies the lexicon is the exclusive storage component of lexemes, usually defined as N(oun), V(erb), and A(djective) stems. The reason for this is that open-class items in lexeme-based models are distinct from closed-class items. Only open-class items require fully specified phonological, grammatical, and semantic representations and therefore require a component discrete from closed class items, which may consist of only a phonological or grammatical representation and which arguably have no semantic representation.
Other properties of lexemes so defined that distinguish them from affixes and other grammatical morphemes is that lexemes are subject to derivation, e.g. employ → employ-er, employ-ee, employ-ment. Affixes certainly are not subject to derivation; they mark derivations. But even free grammatical morphemes such as articles, pronouns, auxiliaries, conjunctions are immune from derivation, so that we do not find productively derived constructions like &hav-er, &thai-ist, &and-ment, or &can-nese.7
Finally, lexemes seem to presuppose grammatical morphemes in that affixes, for instance, apply to lexemes which have undergone derivation but never vice versa. Even free grammatical morphemes do not occur without a real or implied lexeme present. So, for example,. one may say we must go or we go without any presupposition; however, one cannot say we must without an implied verb, i.e. one previously uttered. The same is true of articles like the; one may say cats or the cats but not simply the. This attribute of the relation of lexemes to grammatical morphemes is important in its implication that lexemes are more important in some sense than grammatical morphemes and that they may be copied into utterances before grammatical morphemes are. Further on we adduce evidence from speech error data that this is in fact the case.
2.2.2 Derivation is separate from affixation
In order to explain empty and null morphemes, the semantic 'derivation' of, say, bakes, bake → bake-s, is assumed to be a process independent of the process of spelling out the derivational marker, /s/, on the end of bake to render bakes. The reasons for concluding that derivation is a process separate from affixation are many. First there are the wide-spread phenomena of zero (null) and empty morphemes. While bakes marks the 3rdSg in English, other Person/Number combinations are not marked. One can assume that English simply has no agreement except in 3rdSg for whatever reason since, in this case, the appearance of an articulated expression for agreement is the exception. In the past tense, however, this is not the case. The overwhelming majority of verbs are marked by the suffix -ed, yet a few, like cut and hit have no marker for the Past at all yet they are used without confusion or ambiguity in the Past Tense. The simplest explanation of this is that when someone says, "John hit his brother yesterday," they carry out the Past Tense derivation, but do not phonologically modify the stem.
If this interpretation of omissive morphology is correct, it predicts the opposite phenomena: morphological modification without derivation. This, too, is commonplace among languages. Aronoff (1993) discusses the problem of empty morphemes extensively. The most prominent example of these ubiquitous morphemes are the so-called THEME VOWELS on nouns, verbs, and adjectives. Latin verbs, for example all bear one of five theme vowels except a few with null themes which are marked by the fact that they do not bear them:
| Table 1: Theme Vowels of Latin |
| Conjugation |
Theme |
Present |
| |
Vowel |
Active |
| |
|
Infinitive |
|
| first |
ā |
am-ā-re |
| second |
ē |
del-ē-re |
| third |
e |
leg-e-re |
| third |
i |
cap-i-re |
| third |
Ø |
fer-re |
| fourth |
ī |
aud-ī-re |
Table 1 is taken from Aronoff (1993: 45) where he argues that no meaning may be attributed to the theme morphemes. These are not derivational morphemes like English -ize, -ify, -en as in immorial-ize, pur-ify, thick-en for they occur on all verbs, derived or underived. Yet 'First Conjugation', 'Second Conjugation', and so on, are absolutely inessential in the syntactic or semantic interpretations of Latin verbs. Indeed, they come and go depending on purely phonological and morphological factors without affecting meaning. Conjugation classes are simply a means of directing the verb stems to phonologically variant paradigms and are purely morphological in nature: they have nothing to do with syntax or semantics.
The curious may examine the massive literature on the separation of derivation from affixation in detail in major works of the authors cited here. The conclusions they come to, all based on purely linguistic data, is that these two processes cannot be carried out by the same component because of fundamental differences of the processes involved. Morphological realization, that is, the phonological realization of grammatical morphemes, is a purely phonological process while derivation is the manipulation of grammatical and lexical categories.
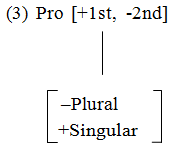
One last point needs to be made. Under the latest variant of lexeme-base morphology, LEXEME-MORPHEME BASE MORPHOLOGY (Beard 1995), the lexicon can also copy its own categories, e.g. [±Singular], [±Feminine], [Class n] into phrase structure in lieu of a fully specified lexeme. The results of this type of copying are pronouns, whether phonologically realized or not. Beard (1995) proposes that pronouns are simply person marking, i.e. [±1st] and [±2nd], as (3) illustrates.
Some lexeme-based theories would originate Singular and Plural features in the NP node as well, but Beard (1982) offers six reasons why Number must be considered a lexical, not an inflectional hence syntactic category. Everyone agrees that Gender is a lexical category which has to be translated into agreement features at the syntactic level.
This stipulation is dependent upon the assumption that derivational processes are independent of morphological realization rules and ideally exemplifies that independence. Many languages do not phonologically realize pronouns aside from agreement affixes on verbs. All languages fail to realize them under certain circumstances (see the literature on Chomsky's 'empty categories'). This stipulation, however, places a strong constraint on what may be a pronoun in any language: pronouns can only comprise the lexical and inflectional categories of lexical items. In his examination of 98 languages from all language families, Beard (1995) found no evidence contradicting this.
2.2.3 Morphemes are purely phonological operations that presuppose lexemes
Under lexeme-based theories, all linguistic means of signaling meaning aside from lexemes is accounted for by morphology, which accounts for all bound and free grammatical morphemes, derivational and inflectional. Crucially, bound inflectional morphemes in a lexeme-based theory are not objects like lexemes but a set of operations which carry out phono-logical modifications (only) of lexical stems. These operation are executed either by an autono-mous morphological spelling component (Beard) or an 'amorphous' device that operates over both the lexicon and syntax (Anderson). Beard even maintains that free grammatical morphemes such as articles, conjunctions, pronouns, adpositions (prepositions and postpositions), and auxiliaries are spelled-out by morphological realization rules after the categories which determine them are provided either by the lexicon (lexical categories) or by functional projections in syntax (inflectional categories). We will proceed with the strong position taken by Beard from this point on.
Specifically, we will assume that the lexicon has nothing to do with phonology or inflection; all inflection is accounted for by functional categories in syntax. Moreover, lexical categories are not manipulated by syntax; rather, categories like Gender must be translated into inflection categories such as Agreement (M-Agreement, F-Agreement, etc.) before they may be manipulated by syntax. All phonological realization of bound or free inflectional or derivational categories is carried out by an autonomous morphological spelling (MS) component which operates between syntax and phonology and, indeed, may be a low-level component of phonology. Beard's LMBM has the strictest modularity of all current lexeme-based theories: modularity is absolute. The lexicon is responsible for lexical derivation (but not its phonological realization); syntax is responsible for inflectional derivation (but not its phonological realization). Both lexical and syntactic phonological realization is carried out by the MS module.
3. Theoretical Predictions
This section will present the predictions of morpheme-based theories resulting from the two assumptions discussed above, (1) that language is based on a single morpheme, it a phonologically variable linguistic sign, all of which are stored in the lexicon, against (2) those of the lexeme-based theory of Beard. We will see that the predictions they make when transparently applied to processing are radically different and serve to distinguish them in a clear and precise manner.
Our assumption here is that if theories of competence are theories of real psychological knowledge, speech errors should be limited both by what we know, i.e. how we categorize it, as well as by how we process that knowledge. No matter what the production model is, it is limited to the categories we know and their arrangement vis-a-vis each other. We simply assume that language processing does not recategorize competence or rearrange the relations between the categories of that knowledge, but rather takes advantage of the highly organized nature of that knowledge. If this reasonable assumption is true, competence theories should transparently project processing model onto mental faculties and capacities. Let us now examine the fundamentals of morpheme-based and lexeme-based morphological theories to see what sort of categories and category arrangements each predicts processing models will access and hence will likely reflect in speech errors.
Morpheme-base theories have nothing to say about the relation of open and closed classes of traditional morphemes; they should presumably behave similarly and reflect similar speech errors except for the phonological differences between bound and free forms. Lexeme-base theories claim that lexemes and morphemes are radically different in the ways in which they convey meaning and hence should be processed in radically different ways, resulting in different types of errors. Specifically, there should be no significant differences between bound and free forms but there should be radical differences between the behavior of lexemes and grammatical morphemes, bound or free, in speech production.
Morpheme-base morphologies predict that derivation is a type of compounding with a semantically and phonologically isomorphic affix added to isomorphic stems. Lexeme-base theories predict a two-step operation: lexical and inflectional (syntactic) derivation followed by phonological spelling. Lexemes are inserted earlier in the derivational process than affixes and other grammatical morphemes. Lexeme-base theories thus allow errors of derivation without errors of realization and vice versa. We will limit this initial investigation to two rather general predictions of morpheme- and lexeme-based theories. Certainly, more detailed analyses are called for. However, our discussion of the two theories thus far has revealed such a striking contrast between their predictions, we have reason to believe that the speech error data will fall robustly in favor of one or the other theory.
4. Competence And Processing
This study will examine four types of speech errors: (1) insertion and deletion of lexemes and morphemes, (2) phonological insertion and deletion in lexemes and (3) morphemes, and (4) a by-product of several others called MORPHOLOGICAL STRANDING in making our case for greater type transparency in grammars with lexeme-base than with morpheme-base morphology. There is considerable variation in the categorization of speech errors across different researchers, so we have attempted to use a more neutral terminology. In the spirit of Dell (1986), we have divided the majority of speech errors into four categories based on common behavior patterns of competence theory: insertion of x, omission of x, repositioning of x, and transposition of x and y. This categorization of speech errors, in addition to being simple and straightforward, is applicable to errors of phonetic features, phonemic segments, syllables, morphemes, words, and phrases. Other categories include 'blend', 'backformation', 'regularization', 'deregularization'; however, we will not refer to these types in our arguments since they either apply to both lexemes and morphemes or apply to one or the other in ways predicted by both morpheme-base and lexeme-base theories.
4.1 Insertion and Omission of Morphemes
Morphemes are frequently inserted and omitted from speech but lexemes apparently are not. The Fromkin selected corpus (Fromkin 1973) contained no examples of either spuriously inserted words or omitted words. Sternberger (1985: XXX) reports just the one in (4):
(4) *I just wanted to_ that, just target: I just wanted to [ask] that
It is difficult to maintain that additional lexemes are not inserted. We found one possible examples of an inserted word, which could be interpreted either as having an additional lexeme inserted or not:
(5) ?The research is all over the military space spectrum
This sentence was uttered in reference to the range of research currently being carried out in Los Alamos. However, whether this is an example of a spuriously inserted word depends upon whether the attribute here is military or military space and it was not possible to stop the speaker and ask. At most, then, lexical insertion and omission is marginal. If lexical insertion is wide-spread, it is accommodated by the speaker's restructuring the phrase to accommodate the lexeme (egg).
Morpheme insertion and omission is commonplace.
(6) MORPHEME INSERTION
| a. *mother'll smelling them |
smell |
| b. *the point about the copulation is ... |
copula |
| c. *tired ... disorientated ... shook up |
disoriented |
| d. *the one exPosner experiment ... |
Posner experiment |
(7) MORPHEME OMISSION
| a. *who could _form at a level |
perform |
| b. *my trouble in _plying |
applying |
| c. *he think_ . . . thinks that Ella's worried |
thinks |
| d. *He relax when you go away |
relaxes |
Lexemes are inserted into syntactic positions which allow only one item without breaking up the phrase, which would cause the speaker to restart. Lexical selection then is not solely dependent upon the lexicon. If lexical selection fails, so does the phrase. This interpretation accommodates the more lax interpretation of the data, that lexical omission and doubling occur but result in restructuring the phrase. The only way an additional lexeme may be inserted into a phrase without restructuring it mid utterance is if it is blended with some other lexeme and 'shoe-horned' into one syntactic position. Blending requires that the words be either phonologically similar (syllable count, position of accent) or semantically similar or both. However, it is quite common in the speech error data.
If morphemes occupied the same sorts of positions, they, too, should be precluded from doubling or being omitted. The fact that they are not implies that they are not subject to syntactic distribution but, according to most lexeme-based theories, are determined by morphological distribution principles, e.g. they replace the brackets of maximal and minimal projections only, as in Beard (1995). If this is the case, then multiple insertions and omissions would be determined by purely morphological principles and their insertion and omission would be a purely morphological matter. If follows that a simple error of the MS component could result in omission or superfluous insertion without causing any syntactic accommodation, only correction of the single error.
4.2 Phonological Errors in Lexemes
Another stark distinction between morphemes and lexemes is that phonological errors of insertion, omission, repositioning, and transposition seem to occur only in the latter.
(8) PHONOLOGICAL INSERTION
| a. *1000 people grate crashed |
gate |
| b. *prudent preople |
people |
More frequently phonemes (or features of phonemes) are repositioned in lexemes:
(9) PHONOLOGICAL REPOSITIONING
| a. *I'll spaint the _tudio |
paint the studio |
| b. *an early mo_ning phorn call |
early morning phone call |
| c. *si_g for the maŋ |
sing for the man |
Not only do such phoneme and feature repositioning errors not occur in grammatical morphemes, when they occur they actually ignore or STRAND any intervening morphemes. Errors such as those in (10) do not occur in our corpus nor have any been mentioned in the literature:
(10) PHONOLOGICAL REPOSITIONING WITH STRANDING
| a. &paint in the thudio |
morpheme-lexeme perseveration |
| b. &paint in ste studio |
morpheme-lexeme anticipation |
| c. &fing sor the man |
morpheme-lexeme transposition |
| d. &sing thor the man |
morpheme-morpheme anticipation |
Let us assume that Beard (1995) is correct in assuming that before affixes may be added to lexemes, the lexical phonological representation of lexemes must be converted into a purely allophonic form, i.e. the lexical representation contains something other than pure phonological features. If affixation (morphological realization or spelling) is a purely phonological process as lexeme-based theories assume, affixation could not take place until this transposition occurs. Thus errors of transposition occurring in the early phases of morphological (and lexical) realization would occur when only morphological categories are present in a phrasal derivation. The phonological representation of grammatical morphemes would not be present. Only after a lexeme is converted to phonological features could the morphological spelling component act upon it to attach affixes or otherwise modify it to mark its morphological categories.
We might attribute the data in (9) and (10) to some purely phonological constraint, say, the prominence of the syllables between which the transposition occurs (Shattuck-Hufnagel 1992 and those she cites). However, phoneme and feature transpositions also occur within lexemes which means that stressed and nonstressed syllables may transpose:
| (11) |
a. *cedars of Lemadon |
Lebanon |
| |
b. *ponato |
tomato |
| |
c. *you're so impetendent |
independent |
The fact of the matter is, prepositions like for and the are clitics in English, which means that they form phonological words with their hosts, e.g. [frðǝmǽn] 'for the man'. Hence any argument relying on phonological prominence will be unstable.
4.3 Evidence of the Separation of Derivation from Affixation
There are errors of morpheme repositioning difficult to interpret, which may be either the results of stray category insertion or a simple realization error.
(12) PHONOLOGICAL REPOSITIONING
| a. *what that add ups to |
adds up to |
| b. *look atting |
looking at |
| c. *even the best team losts |
best teams lost |
Other errors which seem superficially similar are difficult to explain as realization errors:
(13) APPARENT CATEGORY ERRORS
| a. *they broke-dance all night |
they break-danced all night |
| b. *Rosa always date shranks |
dated shrinks |
If these are not random phonological errors (a rarity if such occur at all), the phonological substitutions must be the result of morphological category conditioning, i.e. the mispositioning of the category [+Past). Given the repositioning of the category, the realization will be automatic.
These errors could be explained by a theory which derives words completely in the lexicon and inserts fully inflected forms into phrase structure. Chomsky has recently suggested that this assumption be reexamined. However, the arguments against such a model raised by Matthews (1974), Anderson (1982), and Beard (1995) have not been rebutted and continue to gravely undermine any such model.
4.4 Morphological Stranding
Morphological stranding is so ubiquitous and so mysterious within morpheme-base theories that it deserves a few words of its own. Not only does phonological transposition ignore intervening morphemes, lexeme transposition also ignores grammatical morpheme positions, as (14) illustrates:
| (14) |
a. *it just sounded to start |
started to sound |
| |
b. *fancy getting your model renosed |
nose remodeled |
| |
c. *you have to square it facely |
face it squarely |
| |
d. *he was turking talkish |
talking Turkish |
If words emerged from the lexicon fully derived and inflected, we would expect errors like those in (15).
| (15) |
a. &it just to sounded start |
| |
b. &fancy getting nose your remodeled |
| |
c. &sings she everything she writes |
if not like those of (16):
| (16) |
a. &it justed-start to sound |
| |
b. &fancy getting your nose modelred |
If affixes were selected from the same lexicon as stems, and if they are subcategorized just as are stems, i.e. as Ns, Vs, and As, there is no reason why errors like (15) and (16) would not occur, unless phonological phenomena such as the distribution of accent determines lexical selection. So far no theory of competence or production makes such a claim.
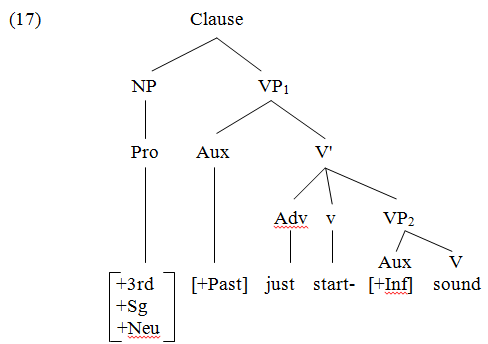
LMBM assumes that deep structure is a categorial component, containing (1) all the
categories needed for inflectional morphology and lexical morphology (word formation), and (2) a lexicon (Chomsky 1993). Thus structures will emerge from deep structure looking like (17). Notice that this structure contains lexeme (N, V, Adj), but no morphemes, only the categories defining morphemes.
The best explanation of why grammatical morphemes are ignored by lexeme transposition errors is that, at the point where the error occurs, they are not phonologically realized (spelled out). If lexical insertion precedes morphological realization, as in all lexeme-based theories, and if language is processed transparently from such a theory, it will be impossible for lexemes and grammatical morphemes to interact.
5. Morpheme-Based Spreading-Activation Theories
I am not the first to notice that lexemes and grammatical morphemes are manifested differently in speech errors. However, other accounts all rest on the assumption that lexemes and grammatical morphemes are essentially identical, linguistic signs, the structuralist 'morpheme'. Our argument is that the difference is accounted for by linguistic differences in the nature of lexemes and grammatical morphemes and not in differences in production mechanisms. For sure, lexemes and grammatical morphemes are generated differently, but under LMBM these differences are dictated by linguistic differences and do not require preferential behavior patterns in production. Those who assume a single lexicon with a single morpheme must explain the differences just discussed in terms of the production model. The most promising alternative approach along these lines is that represented by spreading activation theory.
Dell (1984, 1992) and Dell, Juliano and Govindjee (1993) have constructed a production model based on a single morpheme stored in a single lexicon which belongs to the class of theories including interactive activation models and connectionist models. These theories are distinguished by their assumption of a network of linguistic rules and units which operate when their activation level reaches a threshold. The activation level of a given rule or unit (= node) is controlled by inputs from various surrounding nodes related to it and the threshold is learned.
Speech errors under this set of assumptions are the results of incorrect items with activation levels higher than the correct ones (Dell 1986, 289-90). The spreading-activation network comprises several levels: a semantic level, a syntactic level, a word-level and a phonological level. Each level has its own interconnections of categories and the levels are interconnected, too. Processing is carried out at all levels simultaneously with outputs passed from the semantic to the syntactic to the word level and on to the phonological level. This theory predicts the types of errors discussed in this paper as natural processes: Since activation precedes production, anticipatory errors are predicted by the possibility of an activation threshold of a planned item (word, sound) achieving that of a current item. The same scenario predicts perseveration errors. Most other types of errors are variations and combinations of these two types of activities. Since activation levels are learned via frequency of input, Dell and his colleagues thus postulate that the frequency of an item ultimately determines the distinction between the errors found in lexemes and grammatical morphemes.
The reason for the distinctions between the types and frequency of the errors discussed in this paper is that tokens of closed-class items (bound and free grammatical morphemes) occur in speech more frequently than open-class items, a generally accepted premise and thus their thresholds are better learned. To prove this, Dell (1986) constructed a frequency-based spreading-activation simulation which, according to him, showed that the types of errors produced by his simulation 'exhibit many of the properties present in collections of slips of the tongue' (Dell 1986: 297). Because his initial simulation model did not control for prosody, he admits that his output exhibits too many errors between accented and unaccented syllables and that the output errors often created phonotactically inadmissible output. However, the examples he provides in Table 4 (p. 297) contain another type of error which almost never occur: exchanges between lexemes and grammatical morphemes in different words.
| (17) |
a. (&)typist figure → typig fisture |
| |
b. (&)content convict → concon convict |
The first grammatical morpheme here, -ist, is unaccented and would not alternate with the accented syllable fig- in figure if Dell's model controlled for accent. The second error, however, substitutes the accented con- of convict for the accented -tent of content and so would not be eliminated. Moreover, prosodic controls strong enough to eliminate the errors in (17) would also eliminate phonological exchanges within words like those in (11), where accented an unaccented syllable do replace each other. The problem in both (17a) and (17b) is that a morpheme and lexeme are interacting, and this simply does not occur in normal speech errors.
6. Conclusion
In this note examined a new type of morphological theory, lexeme-base morphology, and compared it with a traditional type, morpheme-base morphology and noted striking differences in the types of speech errors they allow. We then examined the speech error data available in the literature enriched with examples which we ourselves collected over a 3-4 year period. The result shows that lexeme-base models transparently serve as production models in ways that morpheme-base models do not. The importance of this evidence is that it supports Merrill Garrett's contention that there is a fundamental difference between 'closed-class' and 'open-class' morphemes by providing him with a linguistic basis for his arguments.
Even if frequency and accentuation play a role in speech error production, neither explain the linguistic differences between open- and closed-class linguistic items: the fact that zero and empty lexemes never occur, the fact that lexemes are never affixed, never cliticize, and the fact that lexemes undergo lexical derivation but not grammatical morphemes. It would be surprising to find that a class of items like lexemes and a class of processes like those which mark morphemes would be so strikingly different in linguistic terms and yet identical psychological entities.
NOTES
1The research underlying this paper was supported by a grant from the Knight/Bucknell Undergraduate Scholars Program to the author and Meghan Griffith. Griffith contributed to the collection of the speech errors, their analysis, and the arguments derived from that analysis. The paper itself was written by Beard.
2It is ironic that 'possible' and 'impossible terrns' very nearly correlate to the historical terms 'attested' and 'unattested'. This makes sense if we consider that speech error data reflects performance rather than competence and the character of performance is historical while that of competence is ahistorical.
3Halle & Marantz treat grammatical morphemes differently to the extent that they allow their functions in functional projections in syntax. This is their way of accounting for the separation of derivation from affixation. However, their Distributed Morphology remains a morpheme-based theory to the extent that they also list all grammatical morphemes along with lexemes in a single lexicon which they situate after all syntax and just before phonology. We will see further along that their separation of derivational processes from affixational processes allows their theory to predict more of the speech error data than other morpheme-based theories. However, their theory still does not predict as much as a fully fledged lexeme-based theory.
4for the sake of expediency, from time to time we will refer to 'stems' and 'affixes' to distinguish lexical and grammatical morphemes. It is assumed throughout this article that whatever is true morphologically of affixes, is true of other types of morphological marking, i.e. revoweling, reduplication, etc.
5Most theories allow the omission of one or more of these representations in order to account for empty and zero morphemes. This raises two problems which interrelate with troublesome result. First, if nonsign language is a means of transmitting meaning by sound, the question arises of why empty and null morphemes would exist at all. The second problem is that, since stems and affixes are assumed to be essentially identical, morpheme based models are stressed to explain why only grammatical morphemes have zero and empty variants and never lexical morphemes. Because morpheme based morphologies do not distinguish between stems and morphemes but do allow zero and empty morphemes(= stems and affixes), they allow languages which are wholly phonologically null and semantically empty. There are ways to mend these models to prevent this prediction, e.g. the 'overt analogy' constraint (see Xxxxx 1988); however, such amendments can only be externally motivated ancillary subtheories attached to the main theory and ,as of this writing, no theory-driven solution to this problem has been suggested.
6Chomsky (1993, 1994), following suggestions going back as far as Stowell (1983), has recently advanced a new theoretical model, his 'Minimalist Program', that eschews deep structure in favor of lexically defined deep structure relations. The lexicon is the source of deep structure in models of this sort rather than simply the supplier of lexical items for deep structure. However, in all such theories except for Halle & Marantz (1993) the lexical insertion precedes movement and phonology.
7Such derivations may be manufactured unproductively, e. g. she-goat, she-wolf, where she has nothing to do with the grammatical categories 3rd and Singular but only Feminine. Neither lexical nor inflectional derivatives lose features during derivation; thus, these formations cannot be productive lexical derivations. Some grammatical morphemes also have lexical correlates, notably have and be, so that constructions like selfish, the haves and beings do emerge idiomatically in languages. Notice that self in selfish, have in the haves, and be in being are not the grammatical morphemes -self as in her/himself, have as in "I have gone", and be as in "I was going". Rather, the self in the derivative selfish is related lo the noun the self, and have is the lexeme meaning 'lo possess', and be is used in its lexical sense 'to exist'. Even so, all these derivatives are idiomatic hence unproductive since selfish does not mean 'like a self' (cf. boyish, girlish, childish). A being is not anything that exists, that 'is', nor is the suffix -ing a productive agentive suffix. Analogous observations apply to the haves.
REFERENCES
Anderson, Stephen: 1982. "Where's Morphology?" Linguistic Inquiry 13.571-312.
Anderson, Stephen 1992. A-Morphous Morphology. Cambridge: Cambridge University Press.
Anderson, Stephen 1993. "Wackernagel's Revenge: Clitics, Morphology and the Syntax of Second Position". Language 69.68-98.
Anderson, Stephen 1994. "How to Put your Clitics in their Place, or: Why the Best Account of Second-Position Phenomena May be a Nearly Optimal One." Paper presented at the GLOW Workshop, Vienna, April 9, 1994. (To appear in The Linguistic Review.)
Aronoff, Mark 1993. Morphology by Itself; Stems and Inflectional Classes. Cambridge, MA: MIT Press.
Baudouin de Courtenay, Jan 1889. "O zadaniach językoznawstwa". Prace filologiczne 3.92-115. [Translation in Stankiewicz 1972, 125-143].
Beard, Robert 1981. The Indo-European Lexicon: A Full Synchronic Theory. Amsterdam: North-Holland.
Beard, Robert 1982. "Plural as a lexical derivation (word formation)." glossa 16: 133-148
Beard, Robert 1987. "Lexical Stock Expansion". Rules and the Lexicon; Studies in Word Formation, ed. by Edmund Gussmann. Lublin: Catholic University Press, 24-41.
Beard, Robert 1988. "On the Separation of Derivation from Morphology: Toward a Lexeme/ Morpheme Based Morphology". Quaderni di semantica 9.3-59. [Also Indiana University Linguistics Club, 1986].
Beard, Robert 1995. Lexeme-Morpheme Base Morphology. A General Theory of Inflection and Word Formation. Albany: State University of New York Press.
Berwick, Robert and Amy Weinberg 1984. The Grammatical Basis of Linguistic Performance: Language Use and Acquisition. Cambridge, MA: MIT Press.
Bloomfield, Leonard 1933. Language. New York: Henry Holt.
Bloomfield, Leonard 1939. "Menomini Morphophonemics". Travaux du Cercle Linguisiique de Prague 8.105-115.
Bloomfield, Leonard 1962. The Menomini Language. New Haven, Yale University Press.
Chomsky, Noam 1977. Essays on Form and Interpretation. Amsterdan: North Holland.
Chomsky, Noam. 1993. "A minimalist program for linguistic theory". In Hale, Kenneth L. and S. Jay Keyser, eds. The view from Building 20: Essays in linguistics in honor of Sylvain Bromberger. Cambridge, MA: MIT Press. 1–52
Chomsky, Noam. 1995. The Minimalist Program. Cambridge, Mass.: The MIT Press.
Dell, Gary 1986. "A Spreading-Activation Theory of Retrieval in Sentence Production". Psychological Review 93.383-321.
Dell, Gary 1984. "Representation of serial order in speech: evidence from the repeated phoneme effect in speech errors." Journal of Experimental Psychology: Learning, Memory, and Cognition, Vol 10(2), 222-233.
Dell, Gary, Cornell Juliano and Anita Govindjee 1993. "Structure and Content in Language Production: A Theory of Frame Constraints in Phonological Speech Errors". Cognitive Science 17.149-195.
Di Sciullo, Anna-Maria and Edwin Williams 1987. On the definition of word. Linguistic Inquiry
Monographs 14. Cambridge, Massachusetts: MIT Press.
Fromkin, Victoria 1971. "The Non-Anomalous Nature of Anomalous Utterances". Language 47.27-52.
Fromkin, Victoria, ed. 1973. Speech Errors as Linguistic Evidence. Janua Linguarum, Series Maior, 77. The Hague: Mouton.
Garrett, Merrill 1984. "The Organization of Processing Structure for Language Production: Applications to Aphasic Speech". Biological Perspectives on Language, ed. by David Caplan, Andre Lecours and Alan Smith. Cambridge, MA: MIT Press.
Garrett, Merrill 1988. "Processs in Language Production". Linguistics: The Cambridge Survey, Vol. 3. Cambridge: Cambridge University Press, 69-96.
Garrett, Merrill 1992. "Disorders of Lexical Selection". Cognition 42.143-180.
Halle, Morris and Alec Marantz 1993. "Distributed Morphology and the Pieces of Inflection". The View from Building 20, ed. by Kenneth Hale and S. Jay Keyser. Cambridge, MA: MIT Press, 111-176.
Halle, Morris and Alec Marantz 1994. "Position paper". Symposium on Distributed Morphology. LSA Winter Meeting, Boston, MA, January 8, 1994.
Lieber, Rochelle 1992. Deconstructing morphology: Word formation in syntactic theory. Chicago: University of Chicago Press.
Marantz, Alec 1982. "Re: reduplication". Linguistic inquiry, 13.435-482
McCarthy, John 1981. "A Prosodic Theory of Nonconcatenative Morphology". Linguistic
Inquiry 12.373-418.
Matthews, Peter 1972. Inflectional morphology. Cambridge, Cambridge University Press.
Mel'čuk, Igor 1979. "Syntactic or Lexical Zero in Natural Language". Berkeley Linguistics Society 5.224-260.
Motley, Michael, Carl Camden and Bernard Baars 1982. "Covert Formulation and Editing of Anomalies in Speech Production: Evidence from Experimentally Elicited Slips of the Tongue". Journal of Verbal Learning and Verbal Behavior 21.578-594.
Sadock, Jerry 1991. Autolexical Syntax: A Theory of Parallel Grammatical Representations. Chicago: University of Chicago Press.
Selkirk, E. (1982). "The syllable", in van der Hulst, H. & Smith, N. (eds.) The structure of
phonological representations, part II. Dordrecht: Foris. 337-83.
Shattuck-Hufnagel, Stephanie 1992. "Investigation of phonological encoding through speech error analysis: Achievements, limitations, and alternatives". Cognition 42: 181-211.
Stankiewicz, Edward 1972. A Baudouin de Courtenay Anthology. Bloomington: University of Indiana Press.
Sternberger, Joseph 1984. "Structural Errors in Normal and Agrammatic Speech". Cognitive Neuropsychology 1.281-313.
Sternberger, Joseph 1985. The Lexicon in a Model of Language Production. Outstanding Dissertations in Linguistics. New York: Garland.
Sternberger, Joseph 1991. "Apparent Anti-frequency Effects in Language Production: The Addition Bias and Phonological Underspecification". Journal of Memory and Language 30.161-185.
Stowell, Tim 1983. The Origins of Phrase Structure. Ph.D. dissertation. Cambridge, Massachusetts: MIT.
Zwicky, Arnold 1977. On Clitics. Bloomington, IN: Indiana University Linguistics Club.
Zwicky, Arnold 1985. "Clitics and Particles". Language 61.283-305.